5 Visual features drive the category-specific impairments on categorization tasks in a patient with object agnosia
Abstract Object and scene recognition both require mapping of incoming sensory information to existing conceptual knowledge about the world. A notable finding in brain-damaged patients is that they may show differentially impaired performance for specific categories, such as for “living exemplars”. While numerous patients with category-specific impairments have been reported, the explanations for these deficits remain controversial. In the current study, we investigate the ability of a brain-injured patient with a well-established category-specific impairment of semantic memory to perform two categorization experiments: ‘natural’ vs. ‘manmade’ scenes (experiment 1) and ‘living’ vs. ‘non-living’ objects (experiment 2). Our findings show that the pattern of categorical impairment does not respect the natural/living versus manmade/non-living distinction. This suggests that the impairments may be better explained by differences in visual features, rather than by category membership. Using Deep Convolutional Neural Networks (DCNNs) as ‘artificial animal models’ we further explored this idea. Results indicated that DCNNs with ‘lesions’ in higher order layers showed similar response patterns, with decreased relative performance for manmade (experiment 1) and living (experiment 2) items, even though they have no semantic category knowledge, beyond the pure visual domain. Collectively, these results suggest that the direction of category-effects to a large extent depends, at least in MS’ case, on the degree of perceptual differentiation called for.
This chapter is in preparation as: Seijdel, N., Scholte, H.S., & de Haan, E.H.F. (n.d.). Visual features drive the category-specific impairments on categorization tasks in a patient with object agnosia
5.1 Introduction
Object or scene recognition requires mapping of incoming sensory information to existing conceptual knowledge about the world. A notable finding in brain-damaged patients is that they may show differentially impaired knowledge of, most prevalently, living things compared to non-living things (Gainotti, 2000). For many years, researchers have been investigating these category-specific semantic deficits. While they generally have been taken as strong evidence for a disturbance of semantic memory, recent findings have highlighted the importance of controlled experimental tasks and perceptual differences. To date, the debate remains unsettled on how this distinction in breakdown of semantic knowledge along the natural/living versus manmade/non-living axis arises (Capitani et al., 2003; Gainotti, 2000; Young et al., 1989).
Some studies have suggested that evolutionary pressures have led to a specialized, distinct neural mechanism for different categories of knowledge (e.g. animals, plants and artefacts), and that category-specific deficits arise from damage to one of these distinct neural substrates (Caramazza & Shelton, 1998; Nielsen, 1946). However, the most widespread views currently hold that they emerge because living and non-living things have different processing demands (i.e. they rely on different types of information). The first (most dominant) of those theories assumes that the storage of semantic information is divided into parts dominated by different knowledge aspects (e.g. perceptual, functional) and proposes that the dissociation arises from a selective breakdown of perceptual compared to functional associative knowledge. While man-made objects have ‘clearly defined functions’ and are mostly differentiated by their functional qualities, animals have less defining functions and are mostly distinguishable in terms of their visual appearance (Warrington & Shallice, 1984). This ‘differential weighting’ of perceptual and associative attributes might underlie the dissociation between living and non-living things. Later on this theory was revised to also include other modality-specific knowledge channels, such as a ‘motor-related’ channel, to support findings indicating greater impairments for certain more ‘motor-related’ or ‘manipulable’ items (such as tools or kitchen utensils) compared to larger manmade objects (such as vehicles) (Warrington & McCarthy, 1987).
A number of studies have emphasized the importance of intercorrelations amongst individual semantic features. This intercorrelation theory states that concepts are represented as patterns of activation over multiple semantic properties within a unitary distributed system. This intercorrelation theory is appealing in that it does not rely on damage to specific subtypes of attribute (visual, associative, motor) to produce category-specific deficits (Caramazza et al., 1990; Caramazza & Shelton, 1998; Tyler & Moss, 2001).
Another account holds that living items contain a larger number of structurally similar exemplars (e.g. many different types of trees), requiring a more fine-grained visual analysis for successful recognition (Sartori et al., 1993). In order words, it could be inherently more difficult to visually recognize living things compared to non-living things. This view of the structural description system, and their account for category-specific impairments is consistent with work on normal subjects and animal studies (Gaffan & Heywood, 1993). In line with these findings, a more recent study by (Panis et al., 2017) suggested that category-specific impairments may be explained by a deficit in recurrent processing between different levels of visual processing in the inferotemporal cortex. According to them, category-specificity has a perceptual nature, and the direction can shift, depending on perceptual demand. High structural similarity between stored exemplars might be beneficial for integrating local elements and parts into whole representations because the global and local features of these exemplars are more stable and more highly correlated in the real-world than the features from categories with low structural similarity. At the same time however, high structural similarity may be harmful for matching or precise recognition operations, because there may be more competition between the activated representations (Gerlach, 2009).
Here it’s also important to note that different tasks have been used to evaluate patients’ ability to recognize objects from different categories. Category-specific impairments have been established both using semantic memory experiments or visual recognition tasks at different levels (picture naming, picture-word matching, categorization). The differences in perceptual demand for these tasks (i.e. on which perceptual information they depend) might underlie the differences in category-specificity that have previously been found.
In the current study, we investigate the ability of a brain-injured patient with a category-specific impairment of semantic memory to perform scene- and object-categorization tasks (Figure 5.1). This patient, MS, has played a crucial role in the development of theories on category-specificity, showing a very clear category-specific deficit on semantic category fluency tests in previous studies. He has shown to perform better than control participants on non-living categories and significantly worse on living items (Young et al., 1989). A recent study showed that his impairments have remained unchanged for more than 40 years (De Haan et al., 2020). MS‘ problems with living items relative to non-living ones is apparent across a variety of tasks, including mental imagery, retrieval of information and visual recognition (Mehta et al., 1992). However, there is a striking dissociation between MS’ preserved ability to access information about category membership in an implicit test (by priming identification of living and non-living items with related category labels), where there is no difference between the categories, and his severe problems in accessing such information in an explicit test (Young et al., 1989). These findings suggest that it’s an “access” rather than a “storage” problem. Thus, the question remains as to whether MS can access stored representations of visual stimuli and, if so, what the relationships are between perceptual demand, recognition and semantic memory.
Here, two types of questions were addressed. The first - in order to investigate whether or not his category-specific impairment is dependent on perceptual factors - concerned MS’ ability to either categorise visual images as depicting ‘natural’ vs. ‘manmade’ scenes (experiment 1) or to categorise visual objects are ‘living’ vs. ‘non-living’ things (experiment 2). Our findings show a dissociation between the two tasks, with better performance for inanimate objects, compared to animate objects (as is usually the case), and better performance for naturalistic scenes compared to manmade scenes.
The second question concerned the type of computations that might underlie the observed behavior. Recently, a class of computational models, termed deep convolutional neural networks (DCNNs), inspired by the hierarchical architectures of ventral visual streams demonstrated striking similarities with the cascade of processing stages in the human visual system (Cichy et al., 2016; Güçlü & Gerven, 2015; Khaligh-Razavi & Kriegeskorte, 2014). In particular, it has been shown that internal representations of these models are hierarchically similar to neural representations in early visual cortex (V1-V3), mid-level (area V4), and high-level (area IT) cortical regions along the ventral stream. Therefore, we evaluated performance of different DCNN architectures and compared it to MS’ behavior. Results indicated that ‘adding lesions’ to higher-order layers of a DCNN resulted in response patterns similar to those of MS, with decreased performance for manmade (experiment 1) and living (experiment 2) things. Altogether, results from the current study indicate that, at least in specific cases such as MS, category-specific impairments can be explained by perceptual aspects of exemplars within different categories, rather than semantic category-membership.
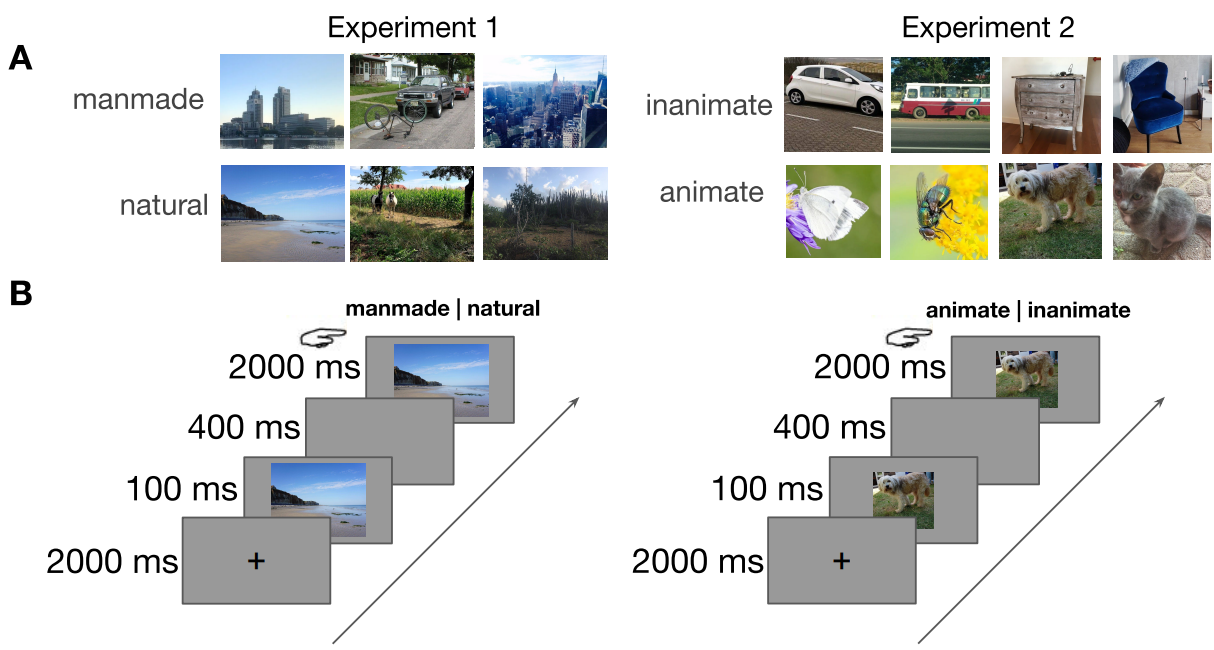
Figure 5.1: Stimuli and experimental paradigm. A) Examples (not part of actual stimulus set) of the two categories in experiment 1 (manmade vs. natural) and experiment 2 (inanimate vs. animate). B) Experimental design. After a 2000 ms blank screen, the stimulus was shown for 100 ms, followed by a 400 ms blank screen. Then, the image reappeared, and MS was asked to categorize the stimulus by pressing the corresponding button.
5.2 Materials and methods
5.2.1 Case history
MS is a former police cadet who contracted herpes encephalitis in 1970 (for a full case description see also Ratcliff (1982)). Most of the ventral temporal cortex of both hemispheres was destroyed, extending to occipital cortex on the right, leaving him with a complete left homonymous hemianopia. He suffers from achromatopsia (Chadwick et al., 2019; Mollon et al., 1980), has severe object agnosia and prosopagnosia (e.g. Newcombe et al. (1989)), but is able to read accurately. His comprehension of what he reads is affected by an impairment of semantic memory. His semantic memory impairment is more marked for living than for non-living things (De Haan et al., 2020; Young et al., 1989).
Anatomical scans (Smits et al., 2019) revealed an, at least partially, intact primary visual cortex (V1) in both hemispheres. Further inspection of the anatomical scan suggests that this part of cortex in the right hemisphere, that could consist of parts of V1 to V4, is disconnected from subsequent cortical areas.
5.2.2 Stimuli
5.2.2.1 Scenes
240 images (640*480 pixels, full-color) of real-world scenes were obtained from a previous unpublished study by Chow-Wing-Bom et al. (2019). Of these 240 images, 80 images were labeled natural (>90% naturalness rating in an independent experiment), 80 images were man-made (<10% naturalness rating) and 80 images were ambiguous (between 10-90% naturalness rating). Ambiguous trials were collected for a different purpose and are not analyzed in the current study. The stimulus set contained a wide variety of different outdoor scenes including beaches, mountains, forests, streets, buildings and parking lots.
5.2.2.2 Objects
80 images (512*512 pixels) of animals (dogs, cats, butterflies and flies) and inanimate objects (cars, busses, cabinets and chairs) were selected from several online databases, including MS COCO (Lin et al., 2014), the SUN database (Xiao et al., 2010), Caltech-256 (Griffin et al., 2007), Open Images V4 (Kuznetsova et al., 2018) and LabelMe (Russell et al., 2008).
5.2.3 Experimental design
During the experiments, stimuli were presented for 100 ms, followed by a 500 ms blank screen. Then, the stimulus reappeared for 2000 ms and MS was asked to categorize the image as accurately as possible using one of two corresponding response buttons. Stimuli were presented in a randomized sequence, at eye-level, in the center of a 23-inch ASUS TFT-LCD display (1920*1080 pixels, at a refresh rate of 60 Hz), while MS was seated approximately 70 cm from the screen. The task was programmed in- and performed using Presentation (Version 18.0, Neurobehavioral Systems Inc., Berkeley, CA, www.neurobs.com). After every 40 trials there was a short break. During the task, EEG was recorded.
5.2.4 Statistical analysis: behavioral data
Choice accuracies were computed for each condition in both experiments (Figure 5.2). Differences between the conditions were tested using two-tailed permutation testing with 5000 permutations. Behavioral data were analyzed and visualized in Python using the following packages: Statsmodels, SciPy, NumPy, Pandas and Seaborn (Jones et al., 2001; McKinney & Others, 2010; Oliphant, 2006; Seabold & Perktold, 2010).
5.2.5 Deep Convolutional Neural Networks (DCNNS)
First, to evaluate how many layers were sufficient to accurately perform the categorization tasks, tests were conducted on four deep residual networks (ResNets; He et al. (2016)) with increasing number of layers; ResNet-6, ResNet-10, ResNet-18 and Resnet-34. Pre-trained networks were fine-tuned to perform either the manmade vs. natural categorization task, or the animate vs. inanimate categorization task, using PyTorch (Paszke et al., 2019). Training data was obtained using the SUN2012 database (Xiao et al., 2010) for manmade an natural scenes, and ImageNet (Russakovsky et al., 2015) for animate and inanimate objects. All sets contained a representative variety of different categories, similar to the stimuli used in the experimental task. Each model was initialized five times with different seeds to perform statistical analyses. For ResNet-10, the most shallow network that was able to successfully perform the task (>95% accuracy on all conditions), we evaluated categorization performance after ‘lesioning’ higher-order layers. To this end, we removed one of the ‘building blocks’, while keeping the skip connection intact.
5.2.6 Data and code availability
Data and code to reproduce the analyses are available at the Open Science Framework (#9h7mf) and at https://github.com/noorseijdel/2020_Object_agnosia.
5.3 Results
First, categorization performance (proportion correct) of MS was computed for both categorization tasks. Results from two-sample permutation tests with 5000 permutations indicated higher performance for natural (experiment 1) and inanimate (experiment 2) images (p = 0.007, p = 0.016, respectively). Thus, in the scene categorization task, MS was significantly better at classifying visually the natural compared to man-made environments. In contrast, on the object categorisation task, he was significantly better at assigning the inanimate than the animate exemplars to the correct category.
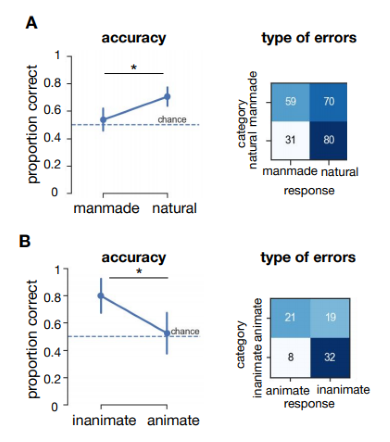
Figure 5.2: Behavioral results of patient MS in experiment 1 and 2. A) Results from experiment 1 (manmade vs. natural) Accuracy (proportion correct) per condition. Horizontal black lines indicate the results of two sample permutation tests, two-tailed using 5000 permutations. Error bars represent the bootstrap 95% confidence interval. * = p < 0.05. B) Results from experiment 2 (animate vs. inanimate).
ResNet-10, -18 and -34 all showed virtually perfect performance for both tasks, for all categories (Figure 5.3). For the most shallow network, ResNet-6, there was a slight decrease in performance, specifically for manmade (experiment 1) and animate objects (p = 0.02, p = 0.03, respectively). Overall these results indicate that performance of a shallow ResNet-6 may decrease in a similar fashion as MS. This supports the idea that performance is decreased for specific categories because those stimuli (in our dataset) are more difficult. Still, even for a shallow ResNet-6, the two-option categorization tasks seems too easy.
Finally, we evaluated the performance of ResNet-10 after ‘lesioning’ higher-order layers (Figure 5.4A). In order to mimic lesions to higher-order areas in the visual processing stream, we removed connections to the final building block of the network (Block 4). Permutation tests with 5000 permutations between ResNet-10 without and with lesion, indicated a decrease in performance after elimination of higher-order layers, specifically for manmade (experiment 1) and animate (experiment 2) images (both p < .001). For natural scenes, there was a slight increase in performance after the removal of higher order layers (p = 0.023). Lesions in earlier layers of the network (blocks 1-3) resulted in a strongly biased response, in which the network generally classified all images as belonging to the same category (Supplementary Figure 5.5). The direction of this bias was variable across different initializations, suggesting that the earlier layers are crucial to obtain a useful representation, and the bias was not caused by the current stimulus set.
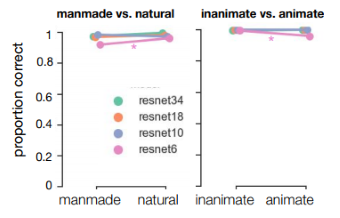
Figure 5.3: Performance of ResNets with different depth (number of layers) on the images from experiment 1 and 2. The ResNets were pretrained on ImageNet, and finetuned on an independent set of manmade and natural scenes and images containing inanimate and animate objects.
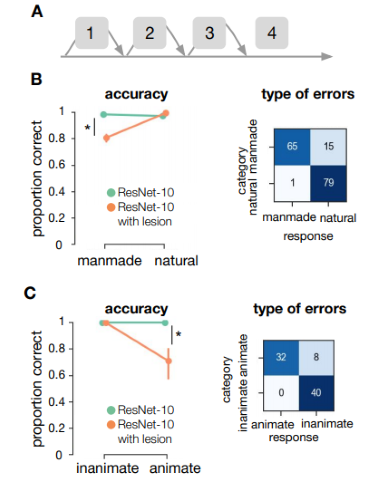
Figure 5.4: ResNet-10 performance on the images from experiment 1 and 2. A) Schematic representation of ResNet-10. ResNet are built by stacking blocks (containing the convolution, batch normalization and pooling operations). Bypassing the different blocks, skip connections add the input directly to the next block. Here, we added a lesion to ResNet-10 by removing block 4. B) Performance of ResNet-10, with and without lesion, on the categorization tasks.
5.4 Discussion
We evaluated the extent to which MS’ ability to recognize visual information shows selective impairments for semantic categories. Our findings show a dissociation between two associated tasks (categorization of manmade vs. natural scenes and animate vs. inanimate objects), with better performance for inanimate objects, compared to animate objects (as is usually the case), and better performance for naturalistic scenes compared to manmade scenes. Overall, these results indicate that the category-specific effects, at least for patient MS, are better explained as a visual impairments, invalidating the idea that this is a purely semantic disorder (i.e. by category membership only). This is in line with earlier findings from Young et al. (1989), and suggests that, similar to findings in earlier studies by Gerlach (2001) and Låg (2005), the direction of category-effects to a large extent depends on the degree of perceptual differentiation called for. Using Deep Convolutional Neural Networks as ‘artificial animal models’ (Scholte, 2018) we further explored the type of computations that might underlie such behavior. Overall, DCNNs with ‘lesions’ in higher order areas showed similar response patterns, with decreased performance for manmade (experiment 1) and living (experiment 2) things.
5.4.1 Category selectivity in the visual ventral stream
There is an ongoing debate on the emergence of category selectivity in the visual ventral stream of healthy subjects. A popular view is that observed category effects indicate a high-level representation in which neurons are organised around either object category or correlated semantic and conceptual features (Konkle & Oliva, 2012; Kriegeskorte et al., 2008; Mahon et al., 2009). An alternative view is that categorical responses in the ventral stream are driven by combinations of more basic visual properties that covary with different categories (Andrews et al., 2015; Long et al., 2018). The conflation of visual and semantic properties in object images means that category-selective responses could be expected under both accounts. Results from the current study do not speak to these findings, nor include/exclude the possibility for object category-selective responses driven by categorical or semantic properties. However, these findings do indicate that in object recognition impairments (following brain damage to certain regions), apparent category-selectivity can emerge based on basic visual properties.
5.4.2 Object representations in IT
A question that remains unresolved in this study is which visual features might be involved in classification of the different categories, i.e. which dimensions in stimulus or object space are utilized by MS. Recent work by Bao et al. (2020) shows that specialization of different categories in certain regions in IT can be explained by two dimensions, progressing from animate to inanimate (dimension 1), and from more stubby to spiky (dimension 2). Following these dimensions, lesions to different parts of IT should lead to agnosias in specific sectors of object space. For example, the observation that MS’ specifically does not recognize insects (which are generally considered more ‘spiky’ than mammals, Supplementary Figure 5.6) as being animate might be explained by a disturbed ‘spiky animate corner’ in object space.
5.4.3 Effect of typicality on category-membership decisions
The typicality of a target object is known to influence category-membership decisions (Shoben, 1982). For a given semantic category, the more typical members can be accepted as belonging to that category more quickly than less typical members. In earlier studies, MS also showed faster reactions to more typical exemplars (Young et al., 1989). However, on top of this ‘typicality effect’, MS showed faster responses to non-living things than living things. In the current study, performance on experiment 2 was merely decreased for insects (Supplementary Figure 5.6). One explanation could be that insects are less typical for the ‘animate’ condition than mammals, and therefore performance was decreased for these images.
5.4.4 Objects vs. scene categorization
Perceiving a scene involves different information than recognition of objects. Object and scene recognition both require mapping of low-level incoming sensory information to high-level representations and semantic knowledge. Following the reverse hierarchy theory (Hochstein & Ahissar, 2002), coarse and global information is extracted before detailed information becomes available. In particular, this theory suggests that the rapid categorization of real-world scenes with minimal effort (Greene & Oliva, 2009b; Potter, 1975) may be mediated by a global percept of the conceptual ‘gist’ of a scene. Thus, low- and mid-level properties may be particularly diagnostic for the behavioral goals specific to scene perception, while object recognition might depend on more extensive processing of high-level properties (Groen, Jahfari, et al., 2018; Groen et al., 2017). In the current study, the natural/man-made distinction may be made before basic-level object distinctions. MS could have relied on this global percept, or ‘gist’ for experiment 1, while this information would not suffice or be informative for experiment 2.
Overall, these results suggest that semantic impairments for certain categories can, at least in MS’ case, be explained by differences in perceptual demand and early visual features, rather than by category membership. Additionally, these findings show that utilizing different DCNN architectures (with and without virtual lesions) offers a promising framework when studying human visual cognition.
5.5 Supplement to Chapter 5
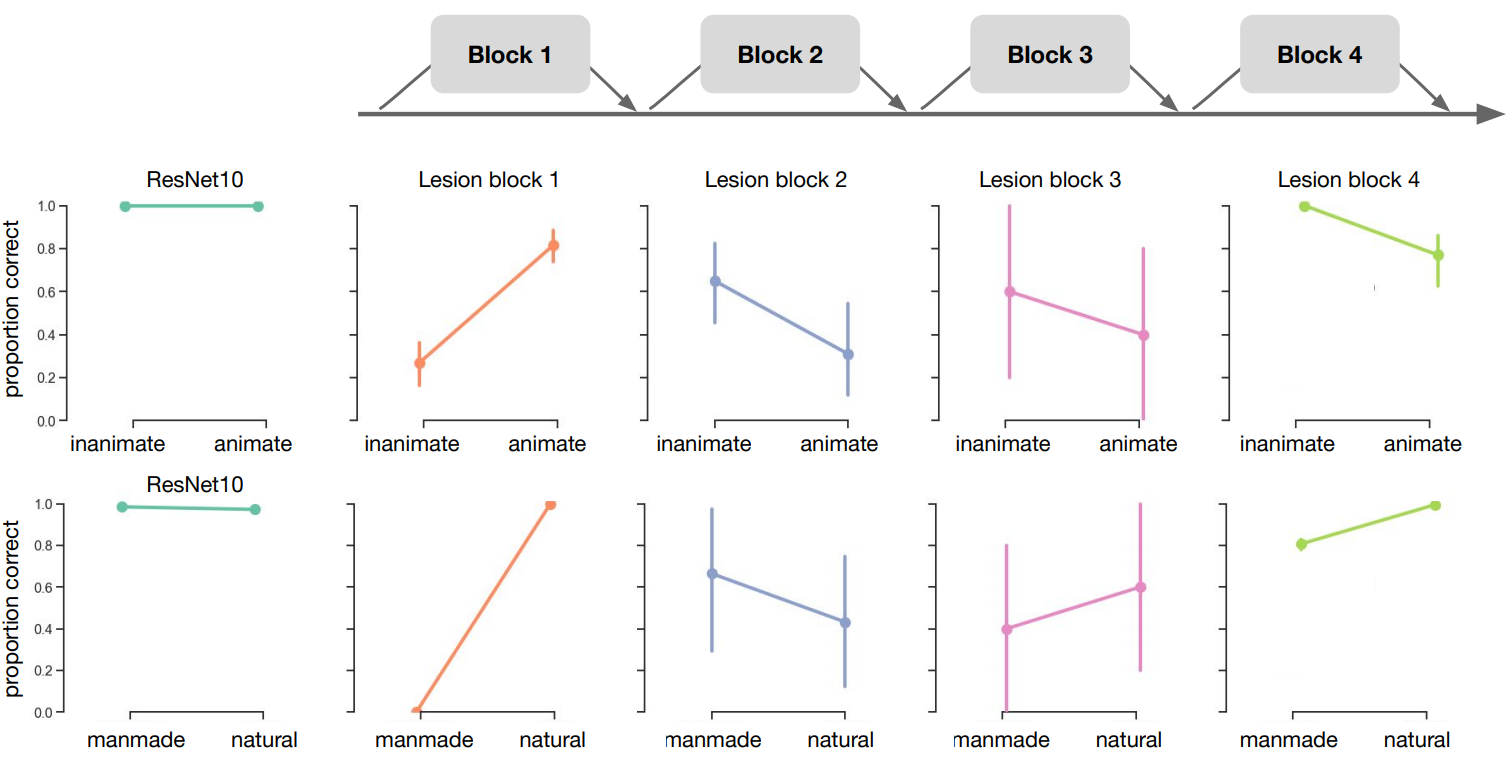
Figure 5.5: ResNet-10 performance on the images from experiment 1 and 2 after removing block 1, 2, 3 and 4.
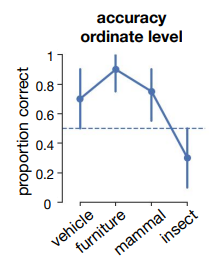
Figure 5.6: Results from experiment 2 (animate vs. inanimate) on the ordinate level.
References
Andrews, T. J., Watson, D. M., Rice, G. E., & Hartley, T. (2015). Low-level properties of natural images predict topographic patterns of neural response in the ventral visual pathway. Journal of Vision, 15(7), 3–3.
Bao, P., She, L., McGill, M., & Tsao, D. Y. (2020). A map of object space in primate inferotemporal cortex. Nature.
Capitani, E., Laiacona, M., Mahon, B., & Caramazza, A. (2003). What are the facts of semantic category-specific deficits? A critical review of the clinical evidence. Cogn. Neuropsychol., 20(3), 213–261.
Caramazza, A., Hillis, A. E., Rapp, B. C., & Romani, C. (1990). The multiple semantics hypothesis: Multiple confusions? Cogn. Neuropsychol., 7(3), 161–189.
Caramazza, A., & Shelton, J. R. (1998). Domain-specific knowledge systems in the brain the animate-inanimate distinction. J. Cogn. Neurosci., 10(1), 1–34.
Chadwick, A., Heywood, C., Smithson, H., & Kentridge, R. (2019). Translucence perception is not dependent on cortical areas critical for processing colour or texture. Neuropsychologia, 128, 209–214.
Chow-Wing-Bom, H. T., Scholte, S., De Klerk, C., Mareschal, D., Groen, I. I. A., & Dekker, T. (2019). Development of rapid extraction of scene gist. PERCEPTION, 48, 40–41.
Cichy, R. M., Pantazis, D., & Oliva, A. (2016). Similarity-Based fusion of MEG and fMRI reveals Spatio-Temporal dynamics in human cortex during visual object recognition. Cereb. Cortex, 26(8), 3563–3579.
De Haan, E. H., Seijdel, N., Kentridge, R. W., & Heywood, C. A. (2020). Plasticity versus chronicity: Stable performance on category fluency 40 years post-onset. Journal of Neuropsychology, 14(1), 20–27.
Gaffan, D., & Heywood, C. A. (1993). A spurious category-specific visual agnosia for living things in normal human and nonhuman primates. J. Cogn. Neurosci., 5(1), 118–128.
Gainotti, G. (2000). What the locus of brain lesion tells us about the nature of the cognitive defect underlying category-specific disorders: A review. Cortex, 36(4), 539–559.
Gerlach, C. (2001). Structural similarity causes different category-effects depending on task characteristics. Neuropsychologia, 39(9), 895–900.
Gerlach, C. (2009). Category-specificity in visual object recognition. Cognition, 111(3), 281–301.
Greene, M. R., & Oliva, A. (2009b). The briefest of glances: The time course of natural scene understanding. Psychol. Sci., 20(4), 464–472.
Griffin, G., Holub, A., & Perona, P. (2007). Caltech-256 object category dataset. 20.
Groen, I. I. A., Jahfari, S., Seijdel, N., Ghebreab, S., Lamme, V. A., & Scholte, H. S. (2018). Scene complexity modulates degree of feedback activity during object detection in natural scenes. PLoS Computational Biology, 14(12), e1006690.
Groen, I. I. A., Silson, E. H., & Baker, C. I. (2017). Contributions of low- and high-level properties to neural processing of visual scenes in the human brain. Philos. Trans. R. Soc. Lond. B Biol. Sci., 372(1714).
Güçlü, U., & Gerven, M. A. J. van. (2015). Deep neural networks reveal a gradient in the complexity of neural representations across the ventral stream. Journal of Neuroscience, 35(27), 10005–10014.
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770–778.
Hochstein, S., & Ahissar, M. (2002). View from the top: Hierarchies and reverse hierarchies in the visual system. Neuron, 36(5), 791–804.
Jones, E., Oliphant, T., Peterson, P., & Others. (2001). SciPy: Open source scientific tools for python.
Khaligh-Razavi, S.-M., & Kriegeskorte, N. (2014). Deep supervised, but not unsupervised, models may explain IT cortical representation. PLoS Comput. Biol., 10(11), e1003915.
Konkle, T., & Oliva, A. (2012). A real-world size organization of object responses in occipitotemporal cortex. Neuron, 74(6), 1114–1124.
Kriegeskorte, N., Mur, M., Ruff, D. A., Kiani, R., Bodurka, J., Esteky, H., Tanaka, K., & Bandettini, P. A. (2008). Matching categorical object representations in inferior temporal cortex of man and monkey. Neuron, 60(6), 1126–1141.
Kuznetsova, A., Rom, H., Alldrin, N., Uijlings, J., Krasin, I., Pont-Tuset, J., Kamali, S., Popov, S., Malloci, M., Duerig, T., & Ferrari, V. (2018). The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. http://arxiv.org/abs/1811.00982
Låg, T. (2005). Category-specific effects in object identification: What is “normal”? Cortex, 41(6), 833–841.
Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., & Zitnick, C. L. (2014). Microsoft COCO: Common objects in context. Computer Vision – ECCV 2014, 740–755.
Long, B., Yu, C.-P., & Konkle, T. (2018). Mid-level visual features underlie the high-level categorical organization of the ventral stream. Proceedings of the National Academy of Sciences, 115(38), E9015–E9024.
Mahon, B. Z., Anzellotti, S., Schwarzbach, J., Zampini, M., & Caramazza, A. (2009). Category-specific organization in the human brain does not require visual experience. Neuron, 63(3), 397–405.
McKinney, W., & Others. (2010). Data structures for statistical computing in python. Proceedings of the 9th Python in Science Conference, 445, 51–56.
Mehta, Z., Newcombe, F., & De Haan, E. (1992). Selective loss of imagery in a case of visual agnosia. Neuropsychologia, 30(7), 645–655.
Mollon, J., Newcombe, F., Polden, P., & Ratcliff, G. (1980). On the presence of three cone mechanisms in a case of total achromatopsia. Colour Vision Deficiencies, 5, 130–135.
Newcombe, F., Young, A. W., & De Haan, E. H. (1989). Prosopagnosia and object agnosia without covert recognition. Neuropsychologia, 27(2), 179–191.
Nielsen, J. M. (1946). Agnosia, apraxia, aphasia: Their value in cerebral localization.
Oliphant, T. E. (2006). A guide to NumPy (Vol. 1). Trelgol Publishing USA.
Panis, S., Torfs, K., Gillebert, C. R., Wagemans, J., & Humphreys, G. W. (2017). Neuropsychological evidence for the temporal dynamics of category-specific naming. Vis. Cogn., 25(1-3), 79–99.
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., & others. (2019). PyTorch: An imperative style, high-performance deep learning library. Advances in Neural Information Processing Systems, 8024–8035.
Potter, M. C. (1975). Meaning in visual search. Science, 187(4180), 965–966.
Ratcliff, G. (1982). Object recognition: Some deductions from the clinical evidence. Normality and Pathology in Cognitive Functions.
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A. C., & Fei-Fei, L. (2015). ImageNet large scale visual recognition challenge. Int. J. Comput. Vis., 115(3), 211–252.
Russell, B. C., Torralba, A., Murphy, K. P., & Freeman, W. T. (2008). LabelMe: A database and Web-Based tool for image annotation. Int. J. Comput. Vis., 77(1-3), 157–173.
Sartori, G., Job, R., Miozzo, M., Zago, S., & Marchiori, G. (1993). Category-specific form-knowledge deficit in a patient with herpes simplex virus encephalitis. J. Clin. Exp. Neuropsychol., 15(2), 280–299.
Scholte, H. S. (2018). Fantastic DNimals and where to find them. In NeuroImage (Vol. 180, pp. 112–113).
Seabold, S., & Perktold, J. (2010). Statsmodels: Econometric and statistical modeling with python. Proceedings of the 9th Python in Science Conference, 57, 61.
Shoben, E. J. (1982). Semantic and lexical decisions. In Handbook of Research Methods in Human Memory and Cognition (pp. 287–314).
Smits, A. R., Seijdel, N., Scholte, H. S., Heywood, C. A., Kentridge, R. W., & De Haan, E. H. F. (2019). Action blindsight and antipointing in a hemianopic patient. Neuropsychologia, 128, 270–275.
Tyler, L. K., & Moss, H. E. (2001). Towards a distributed account of conceptual knowledge. Trends Cogn. Sci., 5(6), 244–252.
Warrington, E. K., & McCarthy, R. A. (1987). Categories of knowledge. Further fractionations and an attempted integration. Brain, 110 ( Pt 5), 1273–1296.
Warrington, E. K., & Shallice, T. (1984). Category specific semantic impairments. Brain, 107 ( Pt 3), 829–854.
Xiao, J., Hays, J., Ehinger, K. A., Oliva, A., & Torralba, A. (2010). SUN database: Large-scale scene recognition from abbey to zoo. 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 3485–3492.
Young, A. W., Newcombe, F., Hellawell, D., & De Haan, E. (1989). Implicit access to semantic information. Brain Cogn., 11(2), 186–209.