1 General introduction
If this introduction were written ten years ago, it could begin with a hymn of praise for the human visual system and its incredible achievement in object recognition. It could emphasize how the brain is the only known system that is able to accurately and efficiently perform this task. Back then, visual object recognition was an extremely difficult computational problem; so difficult that even the most advanced computer models and algorithms were not sufficiently advanced to simulate humans’ incredible performance.
Nowadays however, boosted by larger datasets and growing computational power, advances in artificial neural networks have led to vision systems that are starting to rival human accuracy in basic object recognition tasks. This chapter will still start with a description of the human visual system and its praiseworthy performance. Next, it provides a brief overview of the relevant psychological, neuroscientific and computational work on object recognition. Throughout, it outlines how the work presented in this thesis aims to contribute to our understanding of object recognition in the human brain, and how recent advances in a class of computational models called deep convolutional neural networks might mimic and elucidate the processes underlying human recognition. Finally, a brief overview of the remaining chapters in this thesis is provided.
Seemingly without any effort, our brain makes sense of the light that is projected onto our retina, and in the blink of an eye we recognize the objects surrounding us. Unlike a camera, which simply stores raw visual information projected from the physical world, we understand our environment in terms of a constellation of vivid visual features, structures and objects. This performance is especially impressive given that object recognition is a computationally demanding process. A single object, for example a banana, can generate a virtually infinite number of different retinal projections based on many factors, such as its viewpoint, lighting or its ripeness. Moreover, objects from the same category may vary in color, size, texture and other features. In addition to the objects that we already know, recognition often generalizes easily to new, previously unseen exemplars. To make it even more complicated, objects in the real world rarely appear in isolation. We see the world in scenes, where objects are embedded and often partially occluded in rich and complex surroundings. How does the brain extract and transform diagnostic low-level visual features into robust visual representations, whilst there are so many factors that affect the appearance of natural object categories? And how are these representations mapped onto high-level structure, meaning and memory? Visual perception is the organization, identification and interpretation of visual information in order to represent and understand the outside world. The visual cortex is one of the best characterized areas of the human brain and decades of research have focused on these questions.
1.1 From raw sensory input to complex feature constellations
It all starts when light falls onto the lens of our eyes, and is projected onto our retina. Light is composed of photons, that make up electromagnetic waves. The retina is tiled with four different types of light sensitive photoreceptors that each respond differentially to electromagnetic frequencies. Activation is then fed forward through bipolar cells and ganglion cells, via the optic nerve, of which half of the axons crosses over in the optic chiasm and a synaps in the lateral geniculate nucleus (LGN) to the cortex, with most of the fibers terminating in the primary visual cortex (V1). Apart from V1, many other cortical visual areas have been identified. Early studies with patients with damage to certain areas (lesions) have provided strong evidence that damage to different cortical regions may lead to selective impairments (Bodamer, 1947; Dejerine, 1892; Jackson, 1876; Kleist, 1934; Lewandowsky, 1908; Newcombe, 1969; Wilbrand, 1892; Zeki, 1993), including, for example, achromatopsia (impairment of color vision) and prosopagnosia (impairments in the recognition of faces). Findings from electrophysiological and neuroimaging studies have subsequently identified areas that are specialized to represent different types of information. Some areas preferably respond to simple stimuli such as oriented contrasts (Hubel & Wiesel, 1968) or textures; other areas only become active when a specific (more complex) object is visible, such as a face or a bicycle (Downing et al., 2006; Epstein & Kanwisher, 1998). In the last few decades, researchers have identified more than 40 separate maps in the brain that are selectively tuned to specific visual features, such as color (Zeki et al., 1998) or motion (Zihl et al., 1983). Why has the brain evolved with so many visual areas? The classic hypothesis is that the areas form a hierarchy or a ‘pathway’, in which each area incrementally expands on the representation derived by computations and processing in earlier areas, each time representing the sensory input in a different way. The ventral pathway (also referred to as the “what” pathway) has been shown to play a key role in the computations underlying the identification and recognition of objects (Goodale et al., 1992). This pathway extends from V1 through a series of stages, V2, V3, V4, to the inferior temporal (IT) region. Going forward in this ventral pathway, cell responses gradually become size and position invariant, as well as selective for increasingly complex features. An alternative hypothesis is that for each particular visual feature that we can perceive (e.g. colors or textures), there is a dedicated system in the brain containing several visual maps. These different visual maps designed for various visual tasks such as color or face perception, are then distributed over the posterior brain, involving both more basic processes and higher-order processing (De Haan & Cowey, 2011).
1.2 Feed-forward vs. feedback processing in object recognition
Following a pathway from ‘simple’ to ‘more complex’ feature constellations, object recognition has traditionally been seen as the result of a processing pipeline in which, after detection of low-level features (e.g. edges or orientations), grouping and segmentation of the relevant features form the basis on which higher level operations like object recognition can operate (Riesenhuber & Poggio, 1999; Serre et al., 2005). In this pipeline, grouping of information may occur based on relatively simple cues like motion, orientation or collinearity (Mack et al., 1990). By sequentially building up increasingly complex feature conjunctions, a single feed-forward sweep through this pipeline may suffice to perform ‘core object recognition’1 (DiCarlo et al., 2012; Serre et al., 2007) (Figure 1.1A).
Indeed, the speed and efficiency of behavior suggest that a fast feed-forward buildup of perceptual activity should be sufficient for object recognition. For example, rapid categorization experiments showed that humans produced extremely fast and reliable behavioral responses about the category of objects in natural scenes (Thorpe et al., 1996). If participants only needed to make an eye movement towards the relevant category, this could even be done within 120 ms (Kirchner & Thorpe, 2006). Looking at the brain, electroencephalography (EEG) measures of visual responses to different object categories already started to diverge at 150 ms after stimulus onset (Thorpe et al., 1996; VanRullen & Thorpe, 2001). In this feedforward account of object recognition, the role of the early retinotopic visual cortex (i.e., V1/V2) is limited to performing basic computations of the visual input and feeding the output to higher areas for more complex processing. This seems more probable than the recurrent processing account of object recognition: with roughly ten synapses from the retina to high-level visual areas, that each take around 10-20 ms to transfer information, behavioral responses occurring within 250 ms after stimulus onset are likely to be produced by processing that is largely feed-forward because it is too early for global recurrent processing to play a role (Lamme & Roelfsema, 2000).
However, the visual system is clearly not a strict feed-forward hierarchy: it contains an abundance of horizontal and feedback connections that support recurrent computations (Felleman & Van Essen, 1991). Several studies have suggested that information coded in early visual areas still remains functionally relevant for categorical representations at later time points (Cichy et al., 2014). Moreover, there have been studies showing that the disruption of visual processing, beyond feed-forward stages (e.g. >150 ms after stimulus onset, or after object-selective activation of higher-order areas) can lead to decreased object recognition performance. For example, TMS studies have shown that categorization (Camprodon et al., 2010) and detection (Koivisto et al., 2011) of objects in natural scenes is affected when activity in early visual areas is disrupted after the feed-forward sweep. This suggests that activity in early visual areas (V1/V2) remains functionally important for categorization, even after the ‘first round’ of computations.
Contrary to the classical view of the visual hierarchy, it has been proposed that a rapid, global percept of the input (gist) precedes a slow and detailed analysis of the scene (Biederman, 1972; Hochstein & Ahissar, 2002; Oliva, 2005; Oliva & Schyns, 1997), or accompanies detailed feature extraction (Rousselet et al., 2005; Wolfe et al., 2011).
Recently, a growing body of literature suggests that while feed-forward activity may suffice to recognize isolated objects that are easy to discern, the brain employs increasing feedback or recurrent processing for object recognition under more ‘challenging’ natural conditions (Groen, Jahfari, et al., 2018; Kar et al., 2019; Rajaei et al., 2019; Tang et al., 2018). One way in which feedback is thought to facilitate object recognition is through ‘visual routines’ such as curve tracing and figure-ground segmentation. When performing a visual object recognition task, the visual input (stimulus) elicits a feed-forward drive that rapidly extracts basic image features through feedforward connections (Lamme & Roelfsema, 2000). For simple tasks, such as recognizing whether an object is animate or inanimate, or for recognizing clear, isolated objects in sparse scenes, this set of features might be informative enough for successful recognition. While for more detailed tasks or for detecting objects embedded in more complex scenes, the jumble of visual information (‘clutter’) may forward an inconclusive set of features. For those images, extra visual operations (‘visual routines’), such as scene segmentation and perceptual grouping are required. These processes require feedback activity, because they rely on the integration of line segments and other low-level features that are encoded in early visual areas (Crouzet & Serre, 2011; Epshtein et al., 2008; Hochstein & Ahissar, 2002; Lamme & Roelfsema, 2000; Petro et al., 2014; Roelfsema et al., 1999; Self et al., 2019; Zheng et al., 2010). But when is an image considered complex? And how does the brain pick up that an image is complex and that it should therefore employ more extensive processing?
1.3 Natural scene statistics index complexity
The scenes that we encounter in our everyday environment do not contain randomly sampled pixels, but they adhere to specific low-level regularities called natural scene statistics. Natural scene statistics have been demonstrated to carry diagnostic information about the visual environment: for example, slopes of spatial frequency spectra estimated across different spatial scales and orientations (‘spectral signatures’) are informative of scene category and spatial layout (Greene & Oliva, 2009b, 2009a; Oliva & Torralba, 2001). Similarly, the width and shape of histograms of local edge information estimated using single- and multi-scale non-oriented contrast filters have been shown to systematically differ with scene category and complexity (Brady & Field, 2000; Tadmor & Tolhurst, 2000). Scene complexity reflected in local contrast distributions can be estimated using an early visual receptive field model that outputs two parameters, contrast energy (CE) and spatial coherence (SC), approximating the scale and shape of a Weibull fit to the local contrast distribution (Figure 1.1C). Earlier studies have shown that visual activity evoked by natural scenes can be well described by scene complexity, suggesting that the brain is adapted or tuned to those statistical regularities and potentially using them during visual perception (Brady & Field, 2000; Ghebreab et al., 2009; Scholte et al., 2009).
Importantly, CE and SC are computed in a biologically plausible way, using a simple visual model that simulates neuronal responses in one of the earliest stages of visual processing. Specifically, they are derived by averaging the simulated population response of LGN-like contrast filters across the visual scene (Ghebreab et al., 2009). Similar to other models of representation in early vision (e.g. Rosenholtz et al. (2012)), these two-parameters thus provide a compressed representation of a scene. Given that CE and SC inform about the strength and coherence of edges in a scene, they are possibly involved in the formation of the initial coarse percept of a scene. In turn, by providing the system with a measure of the ‘inherent segmentability’ of the scene, they could serve as a complexity index that affects subsequent computations towards a task-relevant visual representation. Indeed, prior work reported effects of scene complexity on both neural responses and behavior (Groen, Jahfari, et al., 2018), indicating enhanced recurrent activity for more complex scenes.
In Chapter 2 of this thesis, we formally modeled the influence of natural scene complexity on perceptual decision-making in an animal detection task. Differences in complexity were task-irrelevant, i.e. not diagnostic of the presence of the target. Our results indicated that scene complexity modulates perceptual decisions through the speed of information processing and evidence requirements, suggesting that the brain is sensitive to low-level regularities even when the task goal is to extract high-level object category information. Having gathered additional evidence for the behavioral relevance of scene complexity, we attempted to dissociate the contributions of the two different axes describing the image complexity ‘space’ (contrast energy and spatial coherence). In chapter 3, we evaluated whether the effects of complexity on neural responses and behavior could be attributed to the computation of SC and CE directly, as a general measure of complexity, or indirectly, as diagnostic information to estimate other task-relevant scene properties. Using EEG measurements and backward masking, we systematically investigated whether scene complexity influenced the involvement of recurrent processing in object recognition.
To summarize, a growing body of literature suggests that we do not necessarily need to always ‘segment’ the object from the scene, enabling very rapid object recognition. Only when the image is cluttered and chaotic or when we perform specific tasks that rely on explicit encoding of spatial relationships between parts, we need to employ extra ‘visual routines’. While this view seems to mostly emphasize that object recognition relies on the integration of features that exclusively belong to the object, there is also evidence that humans can exploit scene regularities to efficiently search for target objects (Castelhano & Heaven, 2010; Malcolm et al., 2014; Torralba et al., 2006) and use these predictions to facilitate object recognition.
1.4 Interaction between scenes and objects
Much of what we know about object recognition emerged from the study of simple, isolated objects and the evaluation of corresponding behavior and neural activity. Visual objects in the real world, however, rarely appear in isolation; they co-vary with other objects and environments. In turn, a scene often holds clues about the object identity or where to search for it (Auckland et al., 2007; Bar, 2004; Bar & Ullman, 1996; Biederman et al., 1982; Greene et al., 2015; Joubert et al., 2008; Oliva & Torralba, 2007; Sun et al., 2011; Võ et al., 2019; Zimmermann et al., 2010). The real world is structured in predictable ways on multiple levels: object-context relations are usually coherent in terms of their physical and semantic content, and they generally occur in typical configurations. The human visual system seems to be sensitive to this structure. For example, participants show enhanced performance for objects appearing in typical locations (e.g. shoes in the lower visual field), and neural representations are sharper as compared to objects appearing in atypical locations (Kaiser et al., 2019). When multiple scene elements are arranged in typical relative positions, cortical processing is more efficient (Kaiser et al., 2019; Kaiser & Cichy, 2018). Additionally, objects appearing on a congruent background (e.g. a toothbrush in a bathroom) are detected more accurately and quickly than objects in an unexpected environment (Davenport & Potter, 2004; Greene et al., 2015; Munneke et al., 2013). Overall, results show that visual processing is tuned to the properties of the real world. So how does scene information influence object recognition? Different accounts of object recognition in scenes propose different ‘loci’ for contextual effects (Oliva & Torralba, 2007; Võ et al., 2019). It has been argued that a bottom-up visual analysis is sufficient to discriminate between basic level object categories, after which context may influence this process in a top-down manner by priming relevant semantic representations, or by constraining the search space to the most likely objects (e.g. Bar (2003)). Recent studies have also indicated that low-level features of a scene (versus high-level semantic components) can modulate object processing (Lauer et al., 2018; Võ et al., 2019) by showing that seemingly meaningless textures with preserved summary statistics contribute to the effective processing of objects in scenes. In chapter 4 of this thesis, we manipulated information from objects and their backgrounds to better understand how information of the background affects the recognition of objects (Figure 1.1D). Linking human visual processing to performance of models from computer vision (that are described in more detail in the next section) we evaluated what type of computations might underlie the segregation of objects from their backgrounds and the interaction between them.
1.5 Probing cognition with deep convolutional neural networks
As already mentioned in the first paragraph of this chapter, the ‘problem’ of object recognition in natural scenes has not only occupied researchers interested in human behavior. Object recognition in natural scenes is one of the most studied problems in computer vision, in which decades of research have been spent on the development of models that could recognize an object by first segmenting the relevant ‘region’ from the background and tracing its outline. Despite these efforts, such models never reached human-level performance in general object recognition tasks. In 2012, the success of a model called ‘AlexNet’ led to a paradigm shift in the field of computer vision (Krizhevsky et al., 2012). Since then, this class of computational models called deep convolutional neural networks (DCNNs), inspired by the hierarchical architecture of the ventral visual stream, have become the most popular approach to object recognition problems. Compared to earlier object recognition algorithms, DCNNs need relatively little preprocessing. While prior models required, for example, hand-engineering of certain filters and preprocessing steps, DCNNs can learn these things by extensive experience with many different examples. This independence from prior knowledge and human effort in feature design was a major advantage, and led to a huge jump in performance.
1.5.1 DCNNs as models of human visual processing
DCNNs and the visual system share two important characteristics. First, both have receptive fields that increase in size along the hierarchy. DCNNs employ receptive fields that act like filters covering the entire input image to exploit the fact that natural images contain strong spatially local correlations. This mimics how the primate visual cortex efficiently accomplishes visual recognition tasks. Second, the further information progresses in the network, the more complex the features become. Various studies have found striking similarities between the respresentations within the artificial neural networks and the cascade of processing stages in the human visual system. In particular, it has been shown that internal representations of these models are hierarchically similar to neural representations in early visual cortex (V1-V3), mid-level (V4), and high-level (IT) cortical regions along the visual ventral stream. For example, neural activity in early areas of visual cortex, as measured with BOLD-MRI, show the highest correspondence with the early layers of DCNNs while higher cortical areas show the highest correspondence with later DCNN layers (Eickenberg et al., 2017; Güçlü & Gerven, 2015; Seeliger et al., 2018; Seibert et al., 2016; Wen et al., 2018). MEG/EEG studies have furthermore shown that early layers of DCNNs explain more of the variance in neural activity early in time, whereas later layers seem to better explain late activity (Cichy et al., 2016; Ramakrishnan et al., 2016). In addition, DCNNs have been shown to predict neural responses in IT, much better than any other computational model (Khaligh-Razavi & Kriegeskorte, 2014; Kubilius et al., 2018; Schrimpf et al., 2018; Yamins et al., 2014). Based on all these previous findings, it has been argued that DCNNs could function as computational models for biological vision (Kietzmann, McClure, et al., 2019; Kriegeskorte, 2015; Lindsay, 2020).
There are, of course, many limitations and non-trivial differences between DCNNs and the human visual system. For example, while the brain is abundant with lateral and feedback connections (Felleman & Van Essen, 1991), most DCNNs are generally feed-forward. The backpropagation algorithm is not considered biologically-plausible enough to be an approximation of how the visual system learns, and there is a stark difference between the simplicity of the model neurons in neural network models and the complexity of real neurons (to name a few). DCNNs often make different types of errors (e.g. Baker et al. (2018) or Geirhos, Rubisch, et al. (2018)). Moreover, several studies have shown how DCNNS are often overly sensitive to changes in the image that would not fool a human observer (Szegedy et al., 2013), and how adding various types of noise, occlusion or blur or even one pixel to standard images leads to a decrease in recognition performance for DCNNS, while leaving human performance intact (Geirhos, Temme, et al., 2018; Ghodrati et al., 2014; Su et al., 2019). Unlike humans, DCNNs are not robust to simple manipultations and tend to generalize poorly beyond the dataset on which they were trained (Serre, 2019).
Still, DCNNs are capable of solving many of the computational problems during visual processing, and on this merit alone one might argue that they deserve our attention as computational models for the human visual system. Possibly, some of the solutions DCNNs provide are similar to biological vision; at the very least, they can be used to explore and generate new hypotheses about the computational mechanisms (Cichy & Kaiser, 2019). Importantly, DCNNs give us the ability to test and compare their performance to humans. By investigating these models, we can perform experiments that would not be possible otherwise, and subsequently gain new insights into how actual neural networks work.
1.5.2 A zoo of artificial animal models
One way of using deep convolutional neural networks to understand human cognition is by using them in a way similar to how we might utilize animal models (Scholte, 2018). An animal model for cognition typically emerges when an animal shows behavior that can be studied in a systematic fashion; such a model becomes even more interesting when the underlying anatomy, architecture and/or physiology of the animal can be linked to the behavior of interest. Current implementations of DCNNs are being studied mostly because they demonstrate an impressive performance on both object and scene recognition. Since these are computer models, we can easily change the architecture or compare different architectures to evaluate the mechanisms that produce this behavior. For example, we can compare different functional architectures or differences in information flow (e.g. feed-forward vs. recurrent; Kietzmann, Spoerer, et al. (2019)) and compare the performance (Figure 1.1B). Leveraging DCNNs as animal models, in chapter 3, we systematically investigated whether recurrent processing is required for figure-ground segmentation during object recognition, by comparing recognition performance in different feed-forward and recurrent DCNN architectures.
In addition to manipulating the structure of the DCNNs, we can also manipulate visual input and evaluate how different models deal with variations in sensory input (‘psychophysics’) during training (e.g. Xu et al. (2018)) and testing (e.g. Wichmann et al. (2017); Kubilius et al. (2016), Ghodrati et al. (2014); Geirhos et al. (2017)), just like in experiments with human participants. In chapter 4, we controlled the information in objects and backgrounds, as well as the relationship between them to manipulate object-background congruence. We found that with an increase in network depth, there is an increase in the distinction between object- and background information. Importantly, we also found that less deep networks benefited from training on images with objects without a background, while this benefit was decreased or even absent for deeper networks. Overall, our results indicate that scene segmentation, the isolation of an object from its background, is implicitly performed by a network of sufficient depth, without dedicated routines or operations.
Interestingly, DCNNs also allow for the simulation of different ‘learning environments’ or experimental paradigms, by changing the methods and material used during training. For example, by changing initial conditions prior to training (Mehrer et al., 2020), evaluating the influence of training (Storrs et al., 2020), or by training them on different tasks (e.g. to categorize different scene categories, rather than objects (Zhou et al., 2014) to learn more about potential task- or category-related differences in the internal representations and behavior. Groen, Greene, et al. (2018), conducted a series of analyses to assess the contribution of DCNN layers to fMRI responses in scene-selective cortex, comparing DCNNs that were trained using either object or scene labels. While they did not observe strong differences in terms of their ability to explain fMRI responses, the correlation between layers of both networks decreased for higher/later layers. In chapter 5, we show how training models on different goals (manmade vs. natural scenes, or animate vs. inanimate objects) can elucidate the role of perceptual demands during different experiments.
Finally, with these models, we can even ‘damage‘ or ‘lesion’ certain regions in the network and evaluate how this influences the model’s performance. In chapter 5, we evaluated object and scene categorization in a brain-injured patient with severe object agnosia and category-specific impairments. By removing connections to later layers in our artificial network, we ‘mimicked lesions’ to higher-order areas in the visual processing stream, and showed an overlap in response patterns.
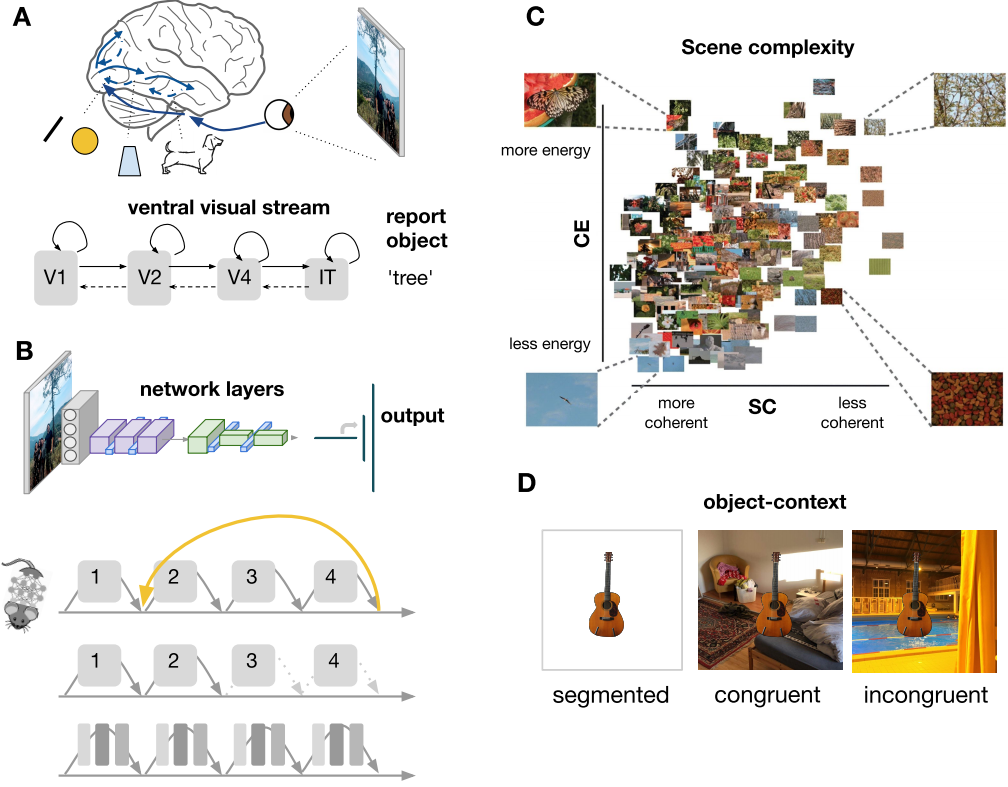
Figure 1.1: Overview of the approach taken in this thesis. A) Schematic representation of visual processing B) Schematic overview of a Deep Convolutional Neural Network (ResNet-10; He et al. (2016)). By comparing feedforward and recurrent DCNNs architectures, ‘lesioning’ or manipulating the network, we can explore the underlying computations that produce behavior. C) scene complexity as indexed by two parameters. Spatial Coherence (SC) describes the shape of the contrast distribution: it varies with the amount of scene fragmentation (scene clutter). Contrast Energy (CE) describes the scale of the contrast distribution: it varies with the distribution of local contrasts strengths.Figure adapted from Groen et al. (2013). D) Example of object-context manipulation by placing objects onto homogenous (segmented), congruent and incongruent backgrounds.
1.6 Aims and outline of this thesis
The main focus of this thesis is to study to what extent the human brain is influenced by real-world properties during object perception. More specifically, it sets out to investigate how different functional architectures or differences in information flow (feedforward vs. recurrent) extract information from objects and their backgrounds during object recognition. Additionally, it showcases a potential role for DCNNs as artificial animal models of human visual processing.
In Chapter 2, participants performed an animal detection task on low, medium or high complexity scenes as determined by two biologically plausible natural scene statistics, contrast energy (CE) or spatial coherence (SC). While prior work already reported effects of scene complexity on neural responses and behavior, these effects were not formally modeled using perceptual decision making models. In addition, there was no in-depth attempt to dissociate the contributions of the two different axes describing the image complexity ‘space’ (CE and SC). Diffusion modeling on the reaction times showed that the speed of information processing was affected by low-level scene complexity. Separate manipulation of the two parameters refined these observations by showing that isolated manipulation of SC resulted in weaker but comparable effects, with an additional change in response boundary, whereas the variation of only CE had no effect.
In Chapter 3, we evaluated whether these behavioral effects were directly based on the computation of SC and CE, as a general measure of image complexity, or indirectly, as diagnostic information to estimate other task-relevant scene properties. Our results suggest the former, as we show that how object recognition is resolved depends on the complexity of the context: for objects presented in isolation or in ‘simple’ environments, object recognition appears to be mostly dependent on the object itself, resulting in a situation that can likely be solved within the first feed-forward sweep of visual information processing. When the environment is more complex, recurrent processing appears to be necessary to group the elements that belong to the object and segregate them from the background.
In Chapter 4, we investigated the extent to which object and context information is represented and used for object recognition in different deep convolutional neural networks. We show that more layers (i.e. a deeper network) are associated with ‘more’ or better segmentation, by virtue of increasing selectivity for relevant constellations of features. This process is similar, at least in terms of its outcome, to figure-ground segmentation in humans and might be one of the ways in which scene segmentation is performed in the brain using recurrent computations.
In Chapter 5, we examined what happens when visual information can no longer be reliably mapped onto existing conceptual knowledge. In this study, we evaluated object and scene categorization in a brain-injured patient MS, with severe object agnosia and category-specific impairments. We show that category-specific effects, at least for patient MS, cannot be explained by a purely semantic disorder (i.e. by category membership only). Using Deep Convolutional Neural Networks as ‘artificial animal models’ we further explored the type of computations that might produce such behavior. Overall, DCNNs with ‘lesions’ in higher order areas showed similar response patterns, with decreased performance for manmade (experiment 1) and living (experiment 2) things.
Finally, in Chapter 6, we summarize the main findings of this thesis and discuss their implications for our understanding of object recognition in natural scenes.
References
Auckland, M. E., Cave, K. R., & Donnelly, N. (2007). Nontarget objects can influence perceptual processes during object recognition. Psychon. Bull. Rev., 14(2), 332–337.
Baker, N., Lu, H., Erlikhman, G., & Kellman, P. J. (2018). Deep convolutional networks do not classify based on global object shape. PLoS Computational Biology, 14(12), e1006613.
Bar, M. (2003). A cortical mechanism for triggering top-down facilitation in visual object recognition. J. Cogn. Neurosci., 15(4), 600–609.
Bar, M. (2004). Visual objects in context. Nature Reviews Neuroscience, 5(8), 617–629.
Bar, M., & Ullman, S. (1996). Spatial context in recognition. Perception, 25(3), 343–352.
Biederman, I. (1972). Perceiving Real-World scenes. Science, 177(4043), 77–80.
Biederman, I., Mezzanotte, R. J., & Rabinowitz, J. C. (1982). Scene perception: Detecting and judging objects undergoing relational violations. Cogn. Psychol., 14(2), 143–177.
Bodamer, J. (1947). Die prosop-agnosie. Archiv Für Psychiatrie Und Nervenkrankheiten, 179(1-2), 6–53.
Brady, N., & Field, D. J. (2000). Local contrast in natural images: Normalisation and coding efficiency. Perception, 29(9), 1041–1055.
Camprodon, J. A., Zohary, E., Brodbeck, V., & Pascual-Leone, A. (2010). Two phases of V1 activity for visual recognition of natural images. J. Cogn. Neurosci., 22(6), 1262–1269.
Castelhano, M. S., & Heaven, C. (2010). The relative contribution of scene context and target features to visual search in scenes. Atten. Percept. Psychophys., 72(5), 1283–1297.
Cichy, R. M., & Kaiser, D. (2019). Deep neural networks as scientific models. Trends in Cognitive Sciences, 23(4), 305–317.
Cichy, R. M., Pantazis, D., & Oliva, A. (2014). Resolving human object recognition in space and time. Nat. Neurosci., 17(3), 1–10.
Cichy, R. M., Pantazis, D., & Oliva, A. (2016). Similarity-Based fusion of MEG and fMRI reveals Spatio-Temporal dynamics in human cortex during visual object recognition. Cereb. Cortex, 26(8), 3563–3579.
Crouzet, S. M., & Serre, T. (2011). What are the visual features underlying rapid object recognition? Front. Psychol., 2, 326.
Davenport, J. L., & Potter, M. C. (2004). Scene consistency in object and background perception. Psychol. Sci., 15(8), 559–564.
De Haan, E. H. F., & Cowey, A. (2011). On the usefulness of “what” and “where” pathways in vision. Trends Cogn. Sci., 15(10), 460–466.
Dejerine, J. (1892). Contribution à l’étude anatomopathologique et clinique des différents variétés de cécité verbale. Mémoires de La Société de Biologie, 4, 61–90.
DiCarlo, J. J., Zoccolan, D., & Rust, N. C. (2012). How does the brain solve visual object recognition? Neuron, 73(3), 415–434.
Downing, P. E., Chan, A.-Y., Peelen, M., Dodds, C., & Kanwisher, N. (2006). Domain specificity in visual cortex. Cerebral Cortex, 16(10), 1453–1461.
Eickenberg, M., Gramfort, A., Varoquaux, G., & Thirion, B. (2017). Seeing it all: Convolutional network layers map the function of the human visual system. Neuroimage, 152, 184–194.
Epshtein, B., Lifshitz, I., & Ullman, S. (2008). Image interpretation by a single bottom-up top-down cycle. Proc. Natl. Acad. Sci. U. S. A., 105(38), 14298–14303.
Epstein, R., & Kanwisher, N. (1998). A cortical representation of the local visual environment. Nature, 392(6676), 598–601.
Felleman, D. J., & Van Essen, D. C. (1991). Distributed hierarchical processing in the primate cerebral cortex. Cereb. Cortex, 1(1), 1–47.
Geirhos, R., Janssen, D. H., Schütt, H. H., Rauber, J., Bethge, M., & Wichmann, F. A. (2017). Comparing deep neural networks against humans: Object recognition when the signal gets weaker. arXiv Preprint arXiv:1706.06969.
Geirhos, R., Rubisch, P., Michaelis, C., Bethge, M., Wichmann, F. A., & Brendel, W. (2018). ImageNet-trained cnns are biased towards texture; increasing shape bias improves accuracy and robustness. arXiv Preprint arXiv:1811.12231.
Geirhos, R., Temme, C. R., Rauber, J., Schütt, H. H., Bethge, M., & Wichmann, F. A. (2018). Generalisation in humans and deep neural networks. Advances in Neural Information Processing Systems, 7538–7550.
Ghebreab, S., Scholte, S., Lamme, V., & Smeulders, A. (2009). A biologically plausible model for rapid natural scene identification. Adv. Neural Inf. Process. Syst., 629–637.
Ghodrati, M., Farzmahdi, A., Rajaei, K., Ebrahimpour, R., & Khaligh-Razavi, S.-M. (2014). Feedforward object-vision models only tolerate small image variations compared to human. Front. Comput. Neurosci., 8, 74.
Goodale, M. A., Milner, A. D., & others. (1992). Separate visual pathways for perception and action.
Greene, M. R., Botros, A. P., Beck, D. M., & Fei-Fei, L. (2015). What you see is what you expect: Rapid scene understanding benefits from prior experience. Atten. Percept. Psychophys., 1239–1251.
Greene, M. R., & Oliva, A. (2009a). Recognition of natural scenes from global properties: Seeing the forest without representing the trees. Cogn. Psychol., 58(2), 137–176.
Greene, M. R., & Oliva, A. (2009b). The briefest of glances: The time course of natural scene understanding. Psychol. Sci., 20(4), 464–472.
Groen, I. I. A., Ghebreab, S., Prins, H., Lamme, V. A. F., & Scholte, H. S. (2013). From image statistics to scene gist: Evoked neural activity reveals transition from Low-Level natural image structure to scene category. Journal of Neuroscience, 33(48), 18814–18824.
Groen, I. I. A., Greene, M. R., Baldassano, C., Fei-Fei, L., Beck, D. M., & Baker, C. I. (2018). Distinct contributions of functional and deep neural network features to representational similarity of scenes in human brain and behavior. Elife, 7, e32962.
Groen, I. I. A., Jahfari, S., Seijdel, N., Ghebreab, S., Lamme, V. A., & Scholte, H. S. (2018). Scene complexity modulates degree of feedback activity during object detection in natural scenes. PLoS Computational Biology, 14(12), e1006690.
Güçlü, U., & Gerven, M. A. J. van. (2015). Deep neural networks reveal a gradient in the complexity of neural representations across the ventral stream. Journal of Neuroscience, 35(27), 10005–10014.
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770–778.
Hochstein, S., & Ahissar, M. (2002). View from the top: Hierarchies and reverse hierarchies in the visual system. Neuron, 36(5), 791–804.
Hubel, D. H., & Wiesel, T. N. (1968). Receptive fields and functional architecture of monkey striate cortex. The Journal of Physiology, 195(1), 215–243.
Jackson, J. H. (1876). Clinical and physiological researches on the nervous system. I. On the localisation of movements in the brain.
Joubert, O. R., Fize, D., Rousselet, G. A., & Fabre-Thorpe, M. (2008). Early interference of context congruence on object processing in rapid visual categorization of natural scenes. J. Vis., 8(13), 11.1–18.
Kaiser, D., & Cichy, R. M. (2018). Typical visual-field locations facilitate access to awareness for everyday objects. Cognition, 180, 118–122.
Kaiser, D., Quek, G. L., Cichy, R. M., & Peelen, M. V. (2019). Object vision in a structured world. Trends Cogn. Sci.
Kar, K., Kubilius, J., Schmidt, K., Issa, E. B., & DiCarlo, J. J. (2019). Evidence that recurrent circuits are critical to the ventral stream’s execution of core object recognition behavior. Nat. Neurosci., 22(6), 974–983.
Khaligh-Razavi, S.-M., & Kriegeskorte, N. (2014). Deep supervised, but not unsupervised, models may explain IT cortical representation. PLoS Comput. Biol., 10(11), e1003915.
Kietzmann, T. C., McClure, P., & Kriegeskorte, N. (2019). Deep neural networks in computational neuroscience. In Oxford research encyclopedia of neuroscience.
Kietzmann, T. C., Spoerer, C. J., Sörensen, L. K. A., Cichy, R. M., Hauk, O., & Kriegeskorte, N. (2019). Recurrence is required to capture the representational dynamics of the human visual system. Proc. Natl. Acad. Sci. U. S. A., 116(43), 21854–21863.
Kirchner, H., & Thorpe, S. J. (2006). Ultra-rapid object detection with saccadic eye movements: Visual processing speed revisited. Vision Res., 46(11), 1762–1776.
Kleist, K. (1934). Gehirnpathologie.
Koivisto, M., Railo, H., Revonsuo, A., Vanni, S., & Salminen-Vaparanta, N. (2011). Recurrent processing in V1/V2 contributes to categorization of natural scenes. J. Neurosci., 31(7), 2488–2492.
Kriegeskorte, N. (2015). Deep neural networks: A new framework for modelling biological vision and brain information processing. In bioRxiv (p. 029876).
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems, 1097–1105.
Kubilius, J., Bracci, S., & Op de Beeck, H. P. (2016). Deep neural networks as a computational model for human shape sensitivity. PLoS Comput. Biol., 12(4), e1004896.
Kubilius, J., Schrimpf, M., Nayebi, A., Bear, D., Yamins, D. L. K., & others. (2018). CORnet: Modeling the neural mechanisms of core object recognition. BioRxiv.
Lamme, V. a F., & Roelfsema, P. R. (2000). The distinct modes of vision offered by feedforward and recurrent processing. Trends Neurosci., 23(11), 571–579.
Lauer, T., Cornelissen, T. H., Draschkow, D., Willenbockel, V., & Võ, M. L.-H. (2018). The role of scene summary statistics in object recognition. Scientific Reports, 8(1), 1–12.
Lewandowsky, M. (1908). Ueber abspaltung des farbensinnes. European Neurology, 23(6), 488–510.
Lindsay, G. (2020). Convolutional neural networks as a model of the visual system: Past, present, and future. J. Cogn. Neurosci., 1–15.
Mack, A., Tuma, R., Kahn, S., & Rock, I. (1990). Perceptual grouping and attention. Bulletin of the Psychonomic Society, 28, 500–500.
Malcolm, G. L., Nuthmann, A., & Schyns, P. G. (2014). Beyond gist: Strategic and incremental information accumulation for scene categorization. Psychol. Sci., 25(5), 1087–1097.
Mehrer, J., Spoerer, C. J., Kriegeskorte, N., & Kietzmann, T. C. (2020). Individual differences among deep neural network models. In bioRxiv (p. 2020.01.08.898288).
Munneke, J., Brentari, V., & Peelen, M. V. (2013). The influence of scene context on object recognition is independent of attentional focus. Front. Psychol., 4, 552.
Newcombe, F. (1969). Missile wounds of the brain: A study of psychological deficits.
Oliva, A. (2005). Gist of the scene. In Neurobiology of attention (pp. 251–256). Elsevier.
Oliva, A., & Schyns, P. G. (1997). Coarse blobs or fine edges? Evidence that information diagnosticity changes the perception of complex visual stimuli. Cogn. Psychol., 34(1), 72–107.
Oliva, A., & Torralba, A. (2001). Modeling the shape of the scene: A holistic representation of the spatial envelope. Int. J. Comput. Vis., 42(3), 145–175.
Oliva, A., & Torralba, A. (2007). The role of context in object recognition. Trends Cogn. Sci., 11(12), 520–527.
Petro, L. S., Vizioli, L., & Muckli, L. (2014). Contributions of cortical feedback to sensory processing in primary visual cortex. Front. Psychol., 5, 1223.
Rajaei, K., Mohsenzadeh, Y., Ebrahimpour, R., & Khaligh-Razavi, S.-M. (2019). Beyond core object recognition: Recurrent processes account for object recognition under occlusion. PLoS Comput. Biol., 15(5), e1007001.
Ramakrishnan, K., Scholte, H. S., Groen, I. I. A., Smeulders, a W. M., & Ghebreab, S. (2016). Summary statistics of deep neural network predict temporal dynamics of object recognition.
Riesenhuber, M., & Poggio, T. (1999). Hierarchical models of object recognition in cortex. Nat. Neurosci., 2(11), 1019–1025.
Roelfsema, P. R., Scholte, H. S., & Spekreijse, H. (1999). Temporal constraints on the grouping of contour segments into spatially extended objects. Vision Res., 39(8), 1509–1529.
Rosenholtz, R., Huang, J., Raj, A., Balas, B. J., & Ilie, L. (2012). A summary statistic representation in peripheral vision explains visual search. J. Vis., 12(4).
Rousselet, G., Joubert, O., & Fabre-Thorpe, M. (2005). How long to get to the “gist” of real-world natural scenes? Visual Cognition, 12(6), 852–877.
Scholte, H. S. (2018). Fantastic DNimals and where to find them. In NeuroImage (Vol. 180, pp. 112–113).
Scholte, H. S., Ghebreab, S., Waldorp, L., Smeulders, A. W. M., & Lamme, V. A. F. (2009). Brain responses strongly correlate with weibull image statistics when processing natural images. J. Vis., 9(4), 29–29.
Schrimpf, M., Kubilius, J., Hong, H., Majaj, N. J., Rajalingham, R., Issa, E. B., Kar, K., Bashivan, P., Prescott-Roy, J., Schmidt, K., Yamins, D. L. K., & DiCarlo, J. J. (2018). Brain-Score: Which artificial neural network for object recognition is most Brain-Like? In bioRxiv (p. 407007).
Seeliger, K., Fritsche, M., Güçlü, U., Schoenmakers, S., Schoffelen, J.-M., Bosch, S., & Van Gerven, M. (2018). Convolutional neural network-based encoding and decoding of visual object recognition in space and time. NeuroImage, 180, 253–266.
Seibert, D., Yamins, D., Ardila, D., Hong, H., DiCarlo, J. J., & Gardner, J. L. (2016). A performance-optimized model of neural responses across the ventral visual stream. bioRxiv, 036475.
Self, M. W., Jeurissen, D., Ham, A. F. van, Vugt, B. van, Poort, J., & Roelfsema, P. R. (2019). The segmentation of Proto-Objects in the monkey primary visual cortex. Curr. Biol., 29(6), 1019–1029.e4.
Serre, T. (2019). Deep learning: The good, the bad, and the ugly. Annual Review of Vision Science, 5, 399–426.
Serre, T., Kouh, M., Cadieu, C., Knoblich, U., Kreiman, G., & Poggio, T. (2005). A theory of object recognition: Computations and circuits in the feedforward path of the ventral stream in primate visual cortex. Artif. Intell., December, 1–130.
Serre, T., Oliva, A., & Poggio, T. (2007). A feedforward architecture accounts for rapid categorization. Proceedings of the National Academy of Sciences, 104(15), 6424–6429.
Storrs, K. R., Kietzmann, T. C., Walther, A., Mehrer, J., & Kriegeskorte, N. (2020). Diverse deep neural networks all predict human it well, after training and fitting. bioRxiv.
Su, J., Vargas, D. V., & Sakurai, K. (2019). One pixel attack for fooling deep neural networks. IEEE Transactions on Evolutionary Computation, 23(5), 828–841.
Sun, H.-M., Simon-Dack, S. L., Gordon, R. D., & Teder, W. A. (2011). Contextual influences on rapid object categorization in natural scenes. Brain Res., 1398, 40–54.
Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., & Fergus, R. (2013). Intriguing properties of neural networks. arXiv Preprint arXiv:1312.6199.
Tadmor, Y., & Tolhurst, D. J. (2000). Calculating the contrasts that retinal ganglion cells and LGN neurones encounter in natural scenes. Vision Res., 40(22), 3145–3157.
Tang, H., Schrimpf, M., Lotter, W., Moerman, C., Paredes, A., Ortega Caro, J., Hardesty, W., Cox, D., & Kreiman, G. (2018). Recurrent computations for visual pattern completion. Proc. Natl. Acad. Sci. U. S. A., 115(35), 8835–8840.
Thorpe, S., Fize, D., & Marlot, C. (1996). Speed of processing in the human visual system. Nature, 381(6582), 520.
Torralba, A., Oliva, A., Castelhano, M. S., & Henderson, J. M. (2006). Contextual guidance of eye movements and attention in real-world scenes: The role of global features in object search. Psychol. Rev., 113(4), 766.
VanRullen, R., & Thorpe, S. J. (2001). The time course of visual processing: From early perception to decision-making. J. Cogn. Neurosci., 13(4), 454–461.
Võ, M. L.-H., Boettcher, S. E., & Draschkow, D. (2019). Reading scenes: How scene grammar guides attention and aids perception in real-world environments. Curr Opin Psychol, 29, 205–210.
Wen, H., Shi, J., Chen, W., & Liu, Z. (2018). Deep residual network predicts cortical representation and organization of visual features for rapid categorization. Scientific Reports, 8(1), 1–17.
Wichmann, F. A., Janssen, D. H., Geirhos, R., Aguilar, G., Schütt, H. H., Maertens, M., & Bethge, M. (2017). Methods and measurements to compare men against machines. Electronic Imaging, 2017(14), 36–45.
Wilbrand, H. (1892). Ein fall von seelenblindheit und hemianopsie mit sectionsbefund. Deutsche Zeitschrift Für Nervenheilkunde, 2(5-6), 361–387.
Wolfe, J. M., Võ, M. L.-H., Evans, K. K., & Greene, M. R. (2011). Visual search in scenes involves selective and nonselective pathways. Trends in Cognitive Sciences, 15(2), 77–84.
Xu, T., Garrod, O., Scholte, S. H., Ince, R., & Schyns, P. G. (2018). Using psychophysical methods to understand mechanisms of face identification in a deep neural network. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW).
Yamins, D. L. K., Hong, H., Cadieu, C. F., Solomon, E. A., Seibert, D., & DiCarlo, J. J. (2014). Performance-optimized hierarchical models predict neural responses in higher visual cortex. Proc. Natl. Acad. Sci. U. S. A., 111(23), 8619–8624.
Zeki, S. (1993). A vision of the brain. Blackwell scientific publications.
Zeki, S., McKeefry, D. J., Bartels, A., & Frackowiak, R. S. (1998). Has a new color area been discovered? Nat. Neurosci., 1(5), 335–336.
Zheng, S., Yuille, A., & Tu, Z. (2010). Detecting object boundaries using low-, mid-, and high-level information. Comput. Vis. Image Underst., 114(10), 1055–1067.
Zhou, B., Lapedriza, A., Xiao, J., Torralba, A., & Oliva, A. (2014). Learning deep features for scene recognition using places database. In Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, & K. Q. Weinberger (Eds.), Advances in neural information processing systems 27 (pp. 487–495). Curran Associates, Inc.
Zihl, J., Cramon, D. von, & Mai, N. (1983). Selective disturbance of movement vision after bilateral brain damage. Brain, 106 (Pt 2), 313–340.
Zimmermann, E., Schnier, F., & Lappe, M. (2010). The contribution of scene context on change detection performance. Vision Res., 50(20), 2062–2068.
The ability to rapidly recognize objects despite substantial appearance variation↩︎